Blog
How we architected a comprehensive metadata system to power real-time market analysis across 20,000+ digital assets, handling everything from basic classifications to complex hierarchical relationships, cross-chain presance and multi-dimensional categorization.

The digital asset sector has grown past simple price feeds. Today, financial institutions – from traders to regulators – demand deep, structured, real-time intelligence. This means understanding an asset's fundamentals, technical setup, governance, and regulatory status, all as it evolves.
Delivering this isn't just a data challenge; it's also a system design challenge. We're building infrastructure specifically to handle the inherent volatility, fragmentation, and multi-chain nature of Web3.
Unlike traditional securities, digital assets are fluid by nature. They rebrand, fork, migrate, change utility, and traverse chains. Legacy systems, built on static identifiers and rigid schemas, simply break under this complexity.
Consider Ethereum. It's a blockchain ecosystem that transitioned from Proof of Work to Proof of Stake, connects multiple rollups and bridges, and affects thousands of dependent assets. A single state change on Ethereum can cascade metadata updates throughout its dependency network.
This isn't a bug; it's a feature - and our architecture is designed to embrace it at scale.
A common pain point: Most existing systems struggle to differentiate between a native token and its bridged or wrapped versions. This leads to critical errors like double-counted Total Value Locked (TVL) metrics, incorrect exchange listings, and significant compliance issues. Imagine building a DeFi protocol or a trading platform without a clear understanding of an asset's true origin and cross-chain presence. We built this system to solve precisely that.
We model every asset through layered dimensions that reflect its evolving nature:
To enrich this metadata and ensure global accessibility, we leverage AI for automated translation of descriptions and technical fields into multiple languages as well as suggestions for asset industries, this is all reviewed by our content team and we'll cover the models used and the processes in a future blog post. This allows our data to serve a worldwide user base efficiently. Regulatory metadata—such as jurisdiction, licensing, audit status, and compliance designations—is tracked per asset and region, making it a powerful tool for institutional due diligence.
At the heart of our system is the Full Asset Metadata API—a single, consistent interface to access our comprehensive metadata You can check the full OpenAPI schema with all the endpoints or specifically just the Asset Metadata one. Clients can request structured metadata for selected assets, tailored by category:
// Fetch detailed metadata for selected assets
const response = await fetch(`https://data-api.coindesk.com/asset/v2/metadata?` + new URLSearchParams({
assets: ['BTC', 'ETH', 'USDC', 'UNI'].join(','),
groups: ['BASIC', 'CLASSIFICATION', 'SUPPLY', 'SOCIAL', 'SUPPORTED_PLATFORMS'].join(','),
quote_asset: 'USD'
}));
const assetData = await response.json();By grouping data into logical segments—BASIC, CLASSIFICATION, SUPPLY, SOCIAL, SUPPORTED_PLATFORMS—clients can minimize bandwidth and maximize relevance.
Our metadata infrastructure is designed for sub-50ms responses, even under volatile, high-throughput workloads, without sacrificing accuracy, consistency, or depth. We've built a hybrid system combining robust relational modeling with low-latency data access and live synchronization (See Fig 1 below).
Updates to asset metadata in PostgreSQL (e.g., supply, tags, classifications) are streamed into Redis via a separate pub/sub messaging cluster for clean separation of roles and scalability.
.png)
Accuracy is enforced through multi-layered validation: cross-source verification, anomaly detection, and a feedback loop where communities and project teams can submit updates. All changes are logged with justification, timestamp, and origin - preserving historical integrity and rollback capability.
Our validation system prioritizes authoritative blockchain data as the primary source of truth, while cross-referencing multiple data aggregators. For supply metrics, we track eight distinct categories: circulating, locked, burnt, staked, issued, total, maximum, and future supply (Fig 2 bellow). Each category helps in understanding an asset's tokenomics and market dynamics.
const calculateSupplyMetrics = (assetId, blockHeight) => {
// Fetch config → Get supply totals from contracts
// Track balances from known addresses (locked, burnt, staked)
// Derive key supply metrics and confidence scores
return { SUPPLY_TOTAL, SUPPLY_CIRCULATING, ... }
}
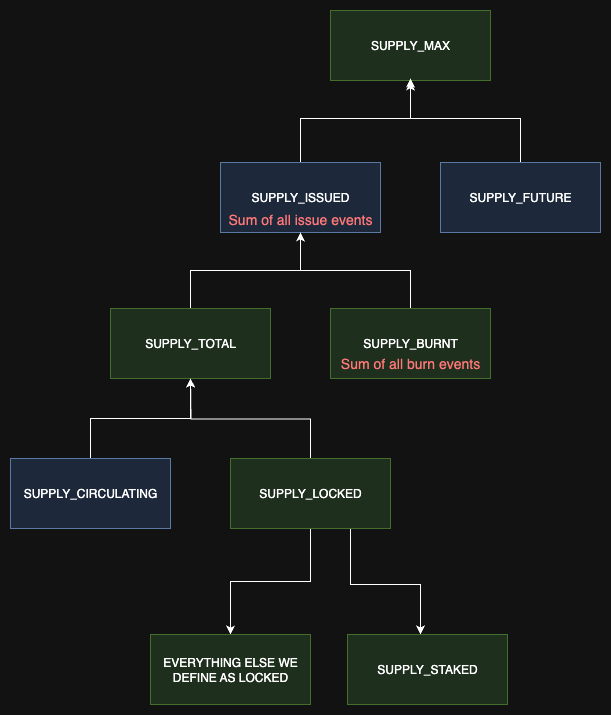
Our content team manually configures which addresses constitute locked, burnt, or staked supply for each asset, ensuring accurate categorization based on project-specific tokenomics. Outlier detection algorithms continuously monitor supply metric changes for statistical anomalies, flagging unexpected shifts for investigation. Each supply calculation receives an internal confidence score based on source reliability, address verification, and cross-reference consistency.
Every supply metric change is logged with a timestamp and source attribution, previous and new values, detailed breakdowns, validation scores, and rollback triggers. This creates a complete audit trail, enabling point-in-time supply queries and selective rollbacks, ensuring our data maintains both accuracy and historical consistency.
Today, most assets span multiple platforms. We model native versus bridged tokens, cross-chain supply attribution, and wrapping risk across bridges. Every asset is resolved per platform with appropriate naming, decimals, and contract references—ensuring complete lineage and eliminating ambiguity.
Our system maintains a canonical asset graph built around parent-child relationships that clearly distinguish between native assets and their wrapped or bridged representations. Each asset has one primary identity on its native blockchain, with all cross-chain versions tracked as separate child assets. This hierarchical structure prevents confusion while maintaining clear lineage and attribution.
We enforce strict platform uniqueness—each asset can have only one contract address per blockchain. However, when a token has multiple implementations on the same chain (e.g., different bridge operators offering competing wrapped versions), we create distinct child assets for each implementation. This ensures accurate supply tracking, prevents double-counting, and maintains clear separation between different bridge operators and their respective wrapped tokens.
// Example: Resolving asset platforms and their relationships
const resolveAssetPlatforms = async (assetId) => {
const parentAsset = await getAssetById(assetId); // Fetch the canonical asset details
const supportedPlatforms = parentAsset.SUPPORTED_PLATFORMS || [];
// Identify the native platform
const nativePlatform = supportedPlatforms.find(platform =>
!platform.IS_INHERITED || platform.BLOCKCHAIN === parentAsset.native_blockchain
);
// Fetch child assets (wrapped/bridged versions)
const childAssets = await getChildAssetsByParentId(assetId);
const bridgedPlatforms = [];
for (const child of childAssets) {
const childPlatforms = child.SUPPORTED_PLATFORMS || [];
// Potentially enrich with bridge operator info if available
const bridgeOperator = await getAssetIssuer(child.ID_ASSET_ISSUER);
bridgedPlatforms.push(...childPlatforms.map(platform => ({
BLOCKCHAIN: platform.BLOCKCHAIN,
BLOCKCHAIN_ASSET_ID: platform.BLOCKCHAIN_ASSET_ID,
TOKEN_STANDARD: platform.TOKEN_STANDARD,
EXPLORER_URL: platform.EXPLORER_URL,
SMART_CONTRACT_ADDRESS: platform.SMART_CONTRACT_ADDRESS,
LAUNCH_DATE: platform.LAUNCH_DATE,
RETIRE_DATE: platform.RETIRE_DATE,
TRADING_AS: platform.TRADING_AS,
DECIMALS: platform.DECIMALS,
IS_INHERITED: true // Flag indicating it's a derived/bridged asset
})));
}
return {
native: nativePlatform,
bridged: bridgedPlatforms,
total_platforms: supportedPlatforms.length + bridgedPlatforms.length
};
};Our system captures comprehensive metadata for each blockchain presence, including blockchain identifier, token standard, smart contract address, launch and retirement dates, trading symbol variations, decimal precision, and explorer URLs. The IS_INHERITED flag automatically distinguishes between native implementations and inherited cross-chain versions.
For supply attribution, we track the backing mechanism behind each bridged instance. Native tokens represent authoritative supply, while bridged versions are attributed based on their backing model. This enables accurate calculation of total circulating supply while preventing double-counting across platforms.
We continuously monitor bridge health and validator sets to assess wrapping risk for each cross-chain instance. Assets with significant bridge exposure receive risk scores that factor into our classification and recommendation systems. When bridges experience issues, affected child assets are automatically flagged, ensuring users understand the operational status and security model of each platform implementation.
Our metadata system powers diverse use cases across the digital asset ecosystem, transforming raw data into actionable insights.
Institutional Compliance and Risk Assessment
DeFi Protocol Integration and Risk Management
Portfolio Construction and Asset Allocation
Research and Market Intelligence
Exchange and Trading Platform Operations
Our metadata system is the foundation for intelligent asset discovery and robust decision-making across the digital asset ecosystem. By providing real-time, comprehensive, and validated metadata, we empower institutions to navigate the complexities of Web3 with speed and confidence.
This architecture is crucial for identifying new opportunities and mitigating risks with unparalleled speed in a constantly evolving market. Our continuous use of AI across key areas – from automating asset listings and processing transaction metadata to refining classifications – significantly streamlines operations for our clients.
Ready to see this power in action? Our Full Asset Metadata API is available for free. Try our endpoint today and unlock a new level of clarity for your digital asset operations: https://developers.coindesk.com/documentation/data-api/asset_v2_metadata
In our next blog posts, we will delve deeper into how our AI-powered systems transform raw metadata into actionable insights, exploring the algorithms that drive real-time asset rankings and keep discovery fresh as the digital asset landscape evolves.
Get our latest research, reports and event news delivered straight to your inbox.